(转)
最近面试了一些Senior BI的候选人,行业经验三年到七年不等,起初觉得这个Level的无需准备笔试题,碍于领导执念,就在真实项目中提取5道SQL题目,这里仅单说其中一道难度中等偏下的题目,抛开面试不谈,单看笔试的话几轮下来答题情况并不理想,至今没有发现有人能写出逻辑滴水不漏又性能最大化的脚本,难点的题目甚至还有交白卷的情况,如果看官觉得这仅仅是茴香豆的茴几种写法的问题就飘过吧,我想通过题目考察的并非只是SQL的熟练程度,相对而言更看重候选人对数据的敏感程度,以及脚本性能的优化能力,往深了说就是要了解数据库存储引擎及查询优化器的工作原理,这是一个合格的BI从业者应有的基本素质。
题目是这样的,有一张ER图描述数据结构,这里就不贴图了,简单文字描述如下,劳烦看官各种脑补主外键关系:
一张会员表(account),字段有会员id(account_id), 会员卡号(account_num)。。。
一张交易订单表(trans),字段有会员id(account_id),交易时间(trans_time),交易金额(sales)。。。
要求查询出所有首笔订单的金额超过1000的会员卡号及其首笔订单金额,
注:
1. 首笔订单指的是每个会员交易时间最小的一笔订单
2. 会员表有一千万笔记录
3. 如果会员没有任何订单或者首笔订单金额<=1000,则首笔订单金额返回0。
下面提供三例典型的答题脚本供参考,候选人BI经验分别是三年,四年,六年,脚本笔录风格太过任性,因为题目没有约束DB产品,所以有使用各种DB私有函数的,有使用join的旧式写法的,甚至还有使用CTE的,状况百出,为照顾看官心情,在尊重原著本意的原则下梳理后的TSQL脚本如下:
A
select a.account_number, t.sales from Account a join ( select account_id, sales, min (trans_time) from trans group by trans_id having sum (sales)>1000 ) t on a.account_id=t.account_id |
B
select a.account_number, t.sales, rank() over(partition by a.account_id order by t.trans_time) rn from account a join trans t on a.account_id=t.account_id where rn=1 and t.sales>1000 group by a.account_number,t.trans_time |
C
Select a.account_number, t.sales From Account a left join ( Select account_id,sales,row_number() over( order by trans_time) rn From Trans ) t on a.account_id=t.account_id where t.rn=1 and t.sales>1000 |
------------------------------------------------2014-12-05---------------------------------------------------------
虽然极力想要表达的是思维的严谨性,但经园友提醒还是发现真要是抠字眼的话,题目的描述也还是有不严谨的地方,例如第三个条件里说的首笔订单金额不足1000,竟然把等于1000这种情况漏掉了,目前为止统计答题情况如下:
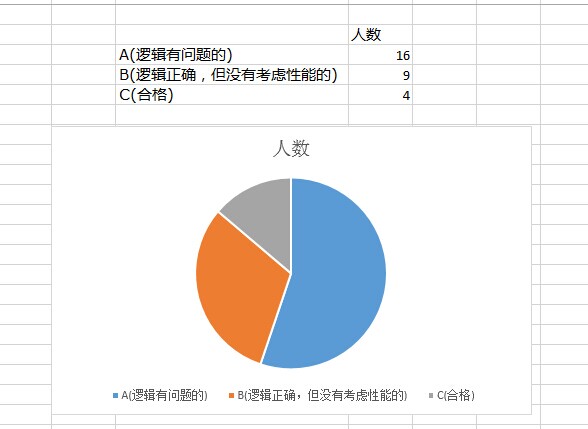
想说点啥呢,我相信大家在机调试的话都能写出逻辑正确的代码,但很多场合下没有时间允许你反复调试代码,甚至有些逻辑错误是无法调试出来的,SQL里的row_number, where, order到底谁先执行,left join 后面的条件写在on后面还是where后面,不经意的写出来都可能是潜在bug,首先得保证数据逻辑正确无误,性能虽是次要,但糟糕的代码积累多了尾大不掉很容易拖垮整个DB,也是要格外小心的事情。
http://www.cnblogs.com/xpivot/p/4143069.html#!comments